目录
- CM1
- 官网
- 下载
- 编译
- 使用
- CM1 darshan
- HACC
- 官网
- 运行HACC
- Github
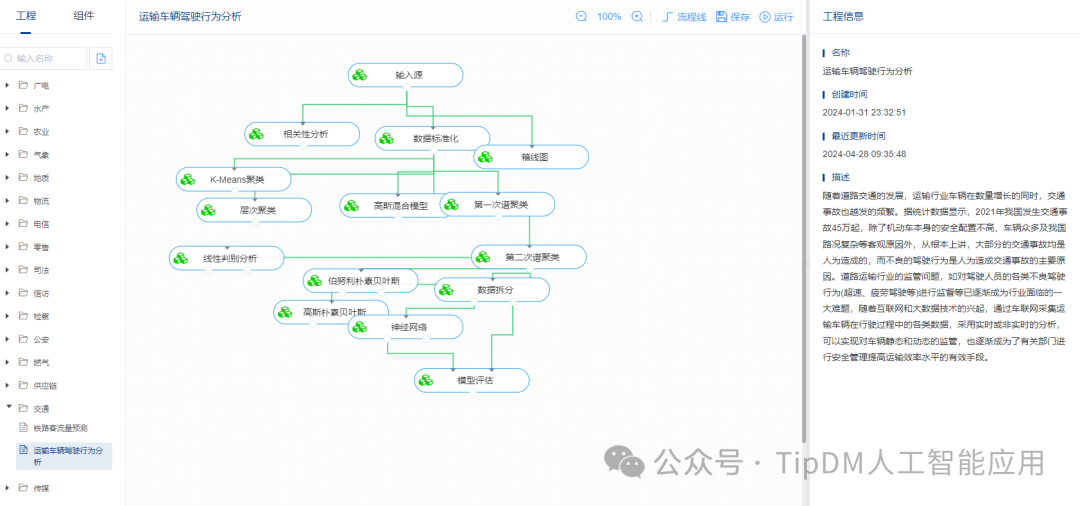
CM1
什么是CM1?用科学术语来说:CM1 是一个三维、非静水力、非线性、随时间变化的数值模型,专为大气现象的理想化研究而设计。用非科学术语来说:CM1 是一个用于大气研究的计算机程序。它专为研究地球大气中相对小规模的过程(例如雷暴)而设计。CM1 是一个三维、随时间变化的非静水数值模型,主要由宾夕法尼亚州立大学 (PSU)(约 2000-2002 年)和 NSF 国家大气研究中心 (NSF NCAR) 的 George Bryan 开发)(2003 年至今)。 CM1 主要是为理想化研究而设计的,特别是深层降水对流(即雷暴)。
官网
https://www2.mmm.ucar.edu/people/bryan/cm1/
下载
https://www2.mmm.ucar.edu/people/bryan/cm1/getcode.html
编译
编辑Makefile,cd 进入src目录。在Makefile中,选择适合您的硬件的操作系统和并行化方法,并取消注释该部分中的所有行。还可以在此文件中设置/更改编译器标志。如果要使用netcdf或hdf5输出,请取消注释Makefile最顶部的相应行,并设置netcdf/hdf5发行版的路径。
#-----------------------------------------------------------------------------
# multiple processors, distributed memory (MPI), Intel compiler
# (default for NCAR's derecho)
FC = /usr/local/bin/mpif90
OPTS = -O3 -ip -assume byterecl -fp-model precise -ftz -no-fma
CPP = cpp -C -P -traditional -Wno-invalid-pp-token -ffreestanding
DM = -DMPI
#-----------------------------------------------------------------------------
# multiple processors, shared memory (OpenMP), Intel compiler
# (can be used for NCAR's derecho)
#FC = mpif90
#OPTS = -O3 -ip -assume byterecl -fp-model precise -ftz -no-fma -qopenmp
#CPP = cpp -C -P -traditional -Wno-invalid-pp-token -ffreestanding
#OMP = -DOPENMP
#-----------------------------------------------------------------------------
# multiple processors, hybrid distributed (MPI) and shared memory (OpenMP), Intel compiler
# (can be used for NCAR's derecho)
#FC = mpif90
#OPTS = -O3 -ip -assume byterecl -fp-model precise -ftz -no-fma -qopenmp
#CPP = cpp -C -P -traditional -Wno-invalid-pp-token -ffreestanding
#DM = -DMPI -DOPENMP
#-----------------------------------------------------------------------------
# single processor, NVIDIA (formerly Portland Group) compiler
#FC = nvfortran
#OPTS = -Mfree -O2 -Ktrap=none -Mautoinline -Minline=reshape
#CPP = cpp -C -P -traditional -Wno-invalid-pp-token -ffreestanding
#-----------------------------------------------------------------------------
OPTS = -O3 -ip -assume byterecl -fp-model precise -ftz -no-fma:这些是编译器优化选项,用于控制编译器如何优化代码。
- -O3:启用高级别优化。
- -ip:生成优化的中间代码以支持多处理器。
- -assume byterecl:假设所有文件都按字节记录。
- -fp-model precise:使用严格的浮点数模型。
- -ftz:将浮点数零化转换为非严格模式。
- -no-fma:禁用融合乘加操作。
CPP = cpp -C -P -traditional -Wno-invalid-pp-token -ffreestanding:这是预处理器选项,用于控制预处理器的行为。
- cpp:预处理器程序。
- -C:保留注释。
- -P:只进行预处理,不进行编译。
- -traditional:使用传统语法。
- -Wno-invalid-pp-token:禁止特定的预处理器警告。
- -ffreestanding:编译为无操作系统支持的程序。
使用
mpirun -np 32 ./cm1.exe
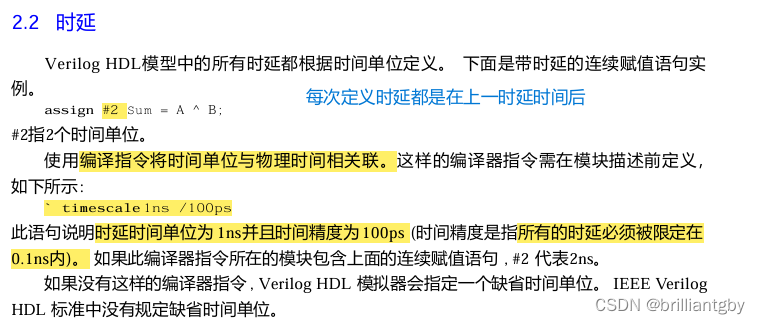
CM1 darshan
# darshan log version: 3.41
# compression method: ZLIB
# exe: /wx/application/cm1r21.0/run/./cm1.exe
# uid: 11366
# jobid: 2896858
# start_time: 1710381946
# start_time_asci: Thu Mar 14 10:05:46 2024
# end_time: 1710382091
# end_time_asci: Thu Mar 14 10:08:11 2024
# nprocs: 160
# run time: 145.1996
# metadata: lib_ver = 3.4.4
# metadata: h = romio_no_indep_rw=true;cb_nodes=4
# log file regions
# -------------------------------------------------------
# header: 1328 bytes (uncompressed)
# job data: 288 bytes (compressed)
# record table: 3711 bytes (compressed)
# POSIX module: 9003 bytes (compressed), ver=4
# LUSTRE module: 936 bytes (compressed), ver=1
# HEATMAP module: 10756 bytes (compressed), ver=1
# mounted file systems (mount point and fs type)
# -------------------------------------------------------
# mount entry: /proc/sys/fs/binfmt_misc autofs
# mount entry: /sys/fs/cgroup/unified cgroup2
# mount entry: /sys/kernel/tracing tracefs
# mount entry: /sys/kernel/config configfs
# mount entry: /sys/fs/cgroup tmpfs
# mount entry: /var/volatile tmpfs
# mount entry: /sys/fs/bpf bpf
# mount entry: /dev/mqueue mqueue
# mount entry: /run/user/0 tmpfs
# mount entry: /run/lock tmpfs
# mount entry: /dev/shm tmpfs
# mount entry: /thfs3 lustre
# mount entry: /thfs1 lustre
# mount entry: /dev devtmpfs
# mount entry: /run tmpfs
# mount entry: / tmpfs
# *******************************************************
# POSIX module data
# *******************************************************
# description of POSIX counters:
# POSIX_*: posix operation counts.
# READS,WRITES,OPENS,SEEKS,STATS,MMAPS,SYNCS,FILENOS,DUPS are types of operations.
# POSIX_RENAME_SOURCES/TARGETS: total count file was source or target of a rename operation
# POSIX_RENAMED_FROM: Darshan record ID of the first rename source, if file was a rename target
# POSIX_MODE: mode that file was opened in.
# POSIX_BYTES_*: total bytes read and written.
# POSIX_MAX_BYTE_*: highest offset byte read and written.
# POSIX_CONSEC_*: number of exactly adjacent reads and writes.
# POSIX_SEQ_*: number of reads and writes from increasing offsets.
# POSIX_RW_SWITCHES: number of times access alternated between read and write.
# POSIX_*_ALIGNMENT: memory and file alignment.
# POSIX_*_NOT_ALIGNED: number of reads and writes that were not aligned.
# POSIX_MAX_*_TIME_SIZE: size of the slowest read and write operations.
# POSIX_SIZE_*_*: histogram of read and write access sizes.
# POSIX_STRIDE*_STRIDE: the four most common strides detected.
# POSIX_STRIDE*_COUNT: count of the four most common strides.
# POSIX_ACCESS*_ACCESS: the four most common access sizes.
# POSIX_ACCESS*_COUNT: count of the four most common access sizes.
# POSIX_*_RANK: rank of the processes that were the fastest and slowest at I/O (for shared files).
# POSIX_*_RANK_BYTES: bytes transferred by the fastest and slowest ranks (for shared files).
# POSIX_F_*_START_TIMESTAMP: timestamp of first open/read/write/close.
# POSIX_F_*_END_TIMESTAMP: timestamp of last open/read/write/close.
# POSIX_F_READ/WRITE/META_TIME: cumulative time spent in read, write, or metadata operations.
# POSIX_F_MAX_*_TIME: duration of the slowest read and write operations.
# POSIX_F_*_RANK_TIME: fastest and slowest I/O time for a single rank (for shared files).
# POSIX_F_VARIANCE_RANK_*: variance of total I/O time and bytes moved for all ranks (for shared files).
# WARNING: POSIX_OPENS counter includes both POSIX_FILENOS and POSIX_DUPS counts
# WARNING: POSIX counters related to file offsets may be incorrect if a file is simultaneously accessed by both POSIX and STDIO (e.g., using fileno())
# - Affected counters include: MAX_BYTE_{READ|WRITTEN}, CONSEC_{READS|WRITES}, SEQ_{READS|WRITES}, {MEM|FILE}_NOT_ALIGNED, STRIDE*_STRIDE
total_POSIX_OPENS: 928
total_POSIX_FILENOS: 0
total_POSIX_DUPS: 0
total_POSIX_READS: 161
total_POSIX_WRITES: 12338
total_POSIX_SEEKS: 269
total_POSIX_STATS: 819
total_POSIX_MMAPS: -1
total_POSIX_FSYNCS: 0
total_POSIX_FDSYNCS: 0
total_POSIX_RENAME_SOURCES: 0
total_POSIX_RENAME_TARGETS: 0
total_POSIX_RENAMED_FROM: 0
total_POSIX_MODE: 384
total_POSIX_BYTES_READ: 1318912
total_POSIX_BYTES_WRITTEN: 979875488
total_POSIX_MAX_BYTE_READ: 8191
total_POSIX_MAX_BYTE_WRITTEN: 341107199
total_POSIX_CONSEC_READS: 0
total_POSIX_CONSEC_WRITES: 11895
total_POSIX_SEQ_READS: 0
total_POSIX_SEQ_WRITES: 12055
total_POSIX_RW_SWITCHES: 0
total_POSIX_MEM_NOT_ALIGNED: 0
total_POSIX_MEM_ALIGNMENT: 8
total_POSIX_FILE_NOT_ALIGNED: 4969
total_POSIX_FILE_ALIGNMENT: 4096
total_POSIX_MAX_READ_TIME_SIZE: 8192
total_POSIX_MAX_WRITE_TIME_SIZE: 115200
total_POSIX_SIZE_READ_0_100: 0
total_POSIX_SIZE_READ_100_1K: 0
total_POSIX_SIZE_READ_1K_10K: 161
total_POSIX_SIZE_READ_10K_100K: 0
total_POSIX_SIZE_READ_100K_1M: 0
total_POSIX_SIZE_READ_1M_4M: 0
total_POSIX_SIZE_READ_4M_10M: 0
total_POSIX_SIZE_READ_10M_100M: 0
total_POSIX_SIZE_READ_100M_1G: 0
total_POSIX_SIZE_READ_1G_PLUS: 0
total_POSIX_SIZE_WRITE_0_100: 20
total_POSIX_SIZE_WRITE_100_1K: 314
total_POSIX_SIZE_WRITE_1K_10K: 382
total_POSIX_SIZE_WRITE_10K_100K: 7194
total_POSIX_SIZE_WRITE_100K_1M: 4428
total_POSIX_SIZE_WRITE_1M_4M: 0
total_POSIX_SIZE_WRITE_4M_10M: 0
total_POSIX_SIZE_WRITE_10M_100M: 0
total_POSIX_SIZE_WRITE_100M_1G: 0
total_POSIX_SIZE_WRITE_1G_PLUS: 0
total_POSIX_STRIDE1_STRIDE: 0
total_POSIX_STRIDE2_STRIDE: 0
total_POSIX_STRIDE3_STRIDE: 0
total_POSIX_STRIDE4_STRIDE: 0
total_POSIX_STRIDE1_COUNT: 0
total_POSIX_STRIDE2_COUNT: 0
total_POSIX_STRIDE3_COUNT: 0
total_POSIX_STRIDE4_COUNT: 0
total_POSIX_ACCESS1_ACCESS: 115200
total_POSIX_ACCESS2_ACCESS: 65536
total_POSIX_ACCESS3_ACCESS: 116160
total_POSIX_ACCESS4_ACCESS: 8192
total_POSIX_ACCESS1_COUNT: 4068
total_POSIX_ACCESS2_COUNT: 7085
total_POSIX_ACCESS3_COUNT: 360
total_POSIX_ACCESS4_COUNT: 161
total_POSIX_FASTEST_RANK: -1
total_POSIX_FASTEST_RANK_BYTES: -1
total_POSIX_SLOWEST_RANK: -1
total_POSIX_SLOWEST_RANK_BYTES: -1
total_POSIX_F_OPEN_START_TIMESTAMP: 0.013255
total_POSIX_F_READ_START_TIMESTAMP: 0.016857
total_POSIX_F_WRITE_START_TIMESTAMP: 0.020553
total_POSIX_F_CLOSE_START_TIMESTAMP: 0.017797
total_POSIX_F_OPEN_END_TIMESTAMP: 145.181315
total_POSIX_F_READ_END_TIMESTAMP: 0.090222
total_POSIX_F_WRITE_END_TIMESTAMP: 145.182856
total_POSIX_F_CLOSE_END_TIMESTAMP: 145.183334
total_POSIX_F_READ_TIME: 0.079693
total_POSIX_F_WRITE_TIME: 4.053917
total_POSIX_F_META_TIME: 1.769984
total_POSIX_F_MAX_READ_TIME: 0.000751
total_POSIX_F_MAX_WRITE_TIME: 0.120138
total_POSIX_F_FASTEST_RANK_TIME: 0.000000
total_POSIX_F_SLOWEST_RANK_TIME: 0.000000
total_POSIX_F_VARIANCE_RANK_TIME: 0.000000
total_POSIX_F_VARIANCE_RANK_BYTES: 0.000000
HACC
基准测试的目的是评估硬件加速宇宙学代码(HACC)模拟的I/O系统性能。HACC框架使用N体技术模拟在膨胀宇宙中受重力影响下无碰撞流体的结构形成。HACC I/O基准测试捕获了HACC模拟代码的I/O模式。这包括模拟产生的检查点和重启以及分析输出。它还捕获了HACC中使用的各种I/O接口,即POSIX I/O、MPI Collective I/O和MPI Independent I/O。此外,基准测试可以将输出写入单个共享文件、每个进程一个文件,或者每组进程一个文件(分区)。构建HACC I/O基准测试的机制是一个仅支持MPI的代码。有一个makefile用于构建基准测试。它依赖于POSIX和MPI-IO。
官网
https://asc.llnl.gov/coral-benchmarks#hacc
运行HACC
fakerth@fakerth-IdeaCentre-GeekPro-17IRB:/opt/software/hacc-io-master$ mpirun -n 4 ./hacc_io 100 ./100.log
-------- Aggregate Performance --------
WRITE Checkpoint Perf: 4068.16 BW[MB/s] 100678496 Bytes 0.0236015 MaxTime[sec]
-------- Aggregate Performance --------
READ Restart Perf: 8656.16 BW[MB/s] 100678496 Bytes 0.011092 MaxTime[sec]
CONTENTS VERIFIED... Success
Github
https://github.com/fakerst/application